SMoDP: Semantically Structured Mixture-of-Experts for Compositional Robotic Manipulation
Abstract
Diffusion-based policies have established a new standard for precise robotic manipulation but face a critical scalability bottleneck: high-performance models are computationally expensive, while lightweight alternatives often fail to generalize across diverse multi-task environments. Mixture-of-Experts (MoE) architectures offer a promising path to efficiency by activating only a subset of parameters. However, existing MoE routing mechanisms typically rely on low-level noise or latent statistics, ignoring the compositional nature of manipulation tasks. This can fragment reusable behaviors across experts, limiting interpretability and transferability.
We introduce Semantically Structured Mixture-of-Experts Diffusion Policy (SMoDP) for compositional robotic manipulation, a framework that grounds expert specialization in semantic task structure. SMoDP leverages a lightweight, inference-time skill predictor, supervised by offline annotations from Vision-Language Models (VLMs), to route action chunks to experts specialized for specific behavioral phases. To ensure robust assignment, we propose a dual contrastive alignment strategy that grounds multi-modal observations in language-defined skill semantics (Inter-modal) while enforcing routing consistency across visually distinct but functionally related behaviors (Intra-modal). Our approach outperforms representative diffusion and MoE-based baselines on multi-task benchmarks with significantly improved parameter efficiency and demonstrates effective compositional transfer to novel tasks through parameter-efficient fine-tuning.
Method Overview
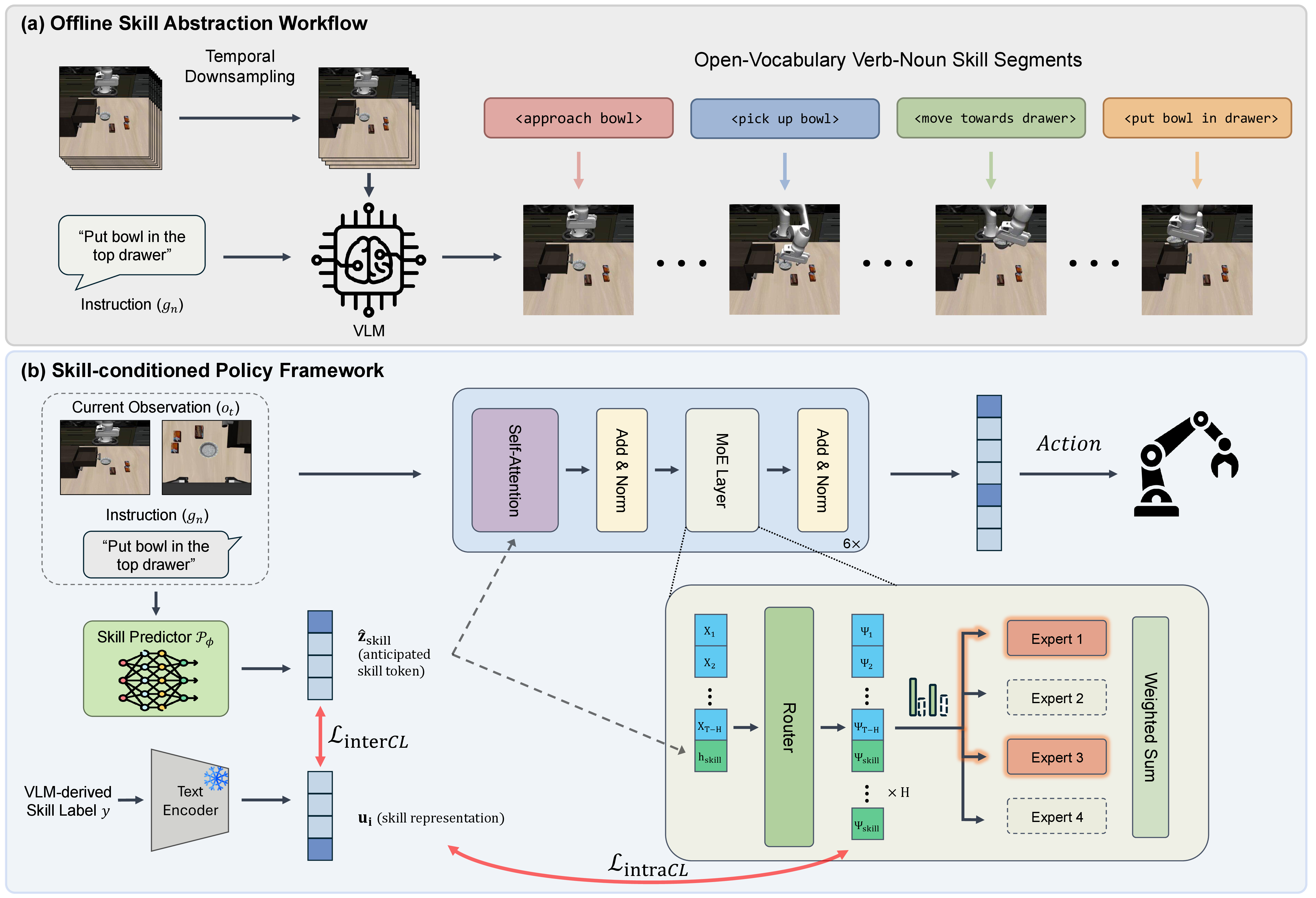
Step 1: Offline Semantic Skill Abstraction. Use a VLM to segment demonstrations into open-vocabulary verb-noun skills, such as <approach bowl>, <pick up bowl>, and <put bowl in drawer>.
Step 2: Lightweight Skill Prediction. Train a compact skill predictor to infer the current or upcoming skill from observation and task instruction, avoiding VLM calls during deployment.
Step 3: Skill-Conditioned Expert Routing. Use the predicted skill embedding to route action chunks through semantically aligned MoE experts, with contrastive alignment encouraging related skills to share expert usage.
Experimental Overview
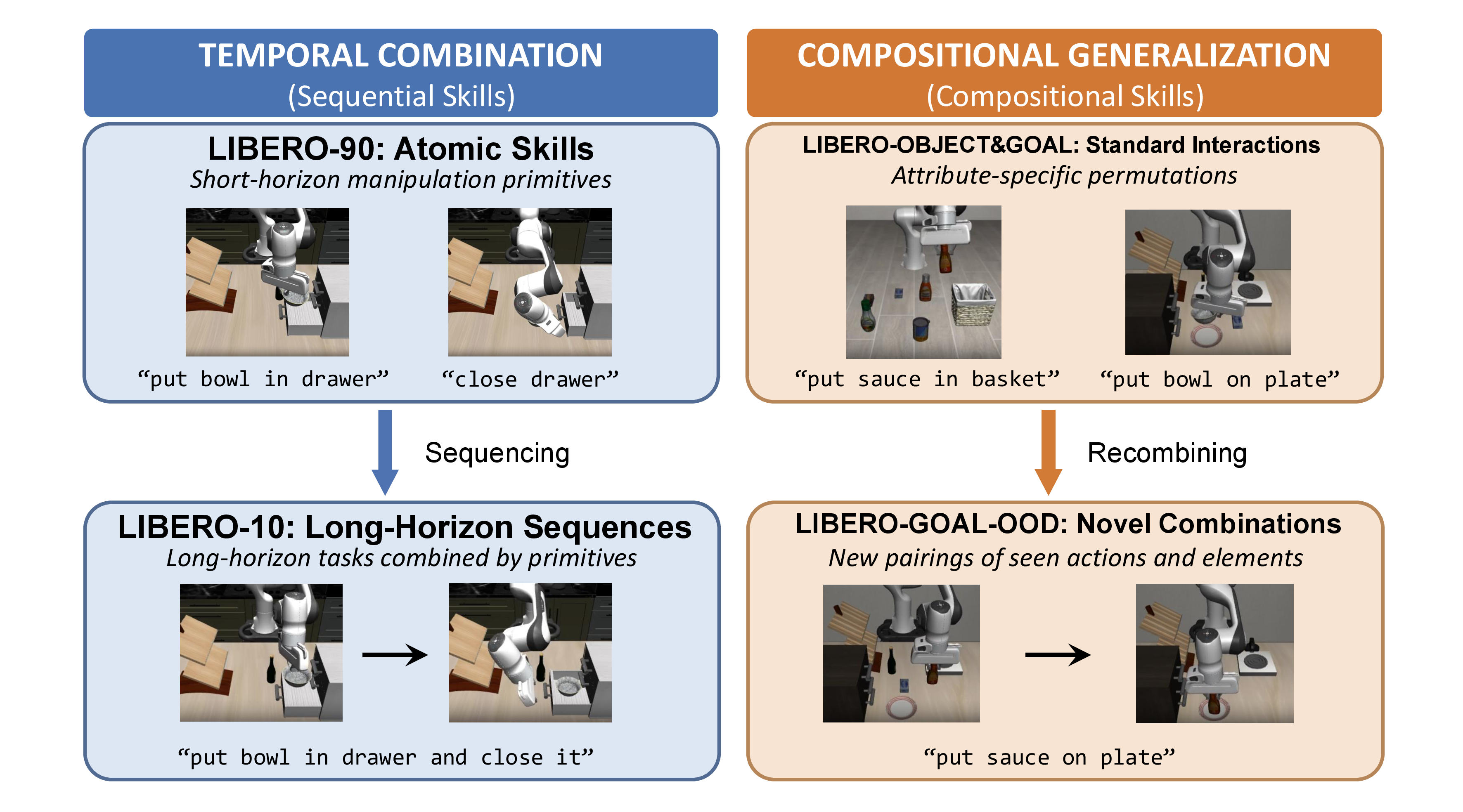

We evaluate SMoDP on LIBERO-10, LIBERO-90, LIBERO-OBJECT, LIBERO-GOAL, LIBERO-GOAL-OOD, and four real-world bimanual ALOHA tasks. Baselines include diffusion policies, Quest, Sparse Diffusion Policy, MoDE, and MoDE with large-scale pretraining.
Results
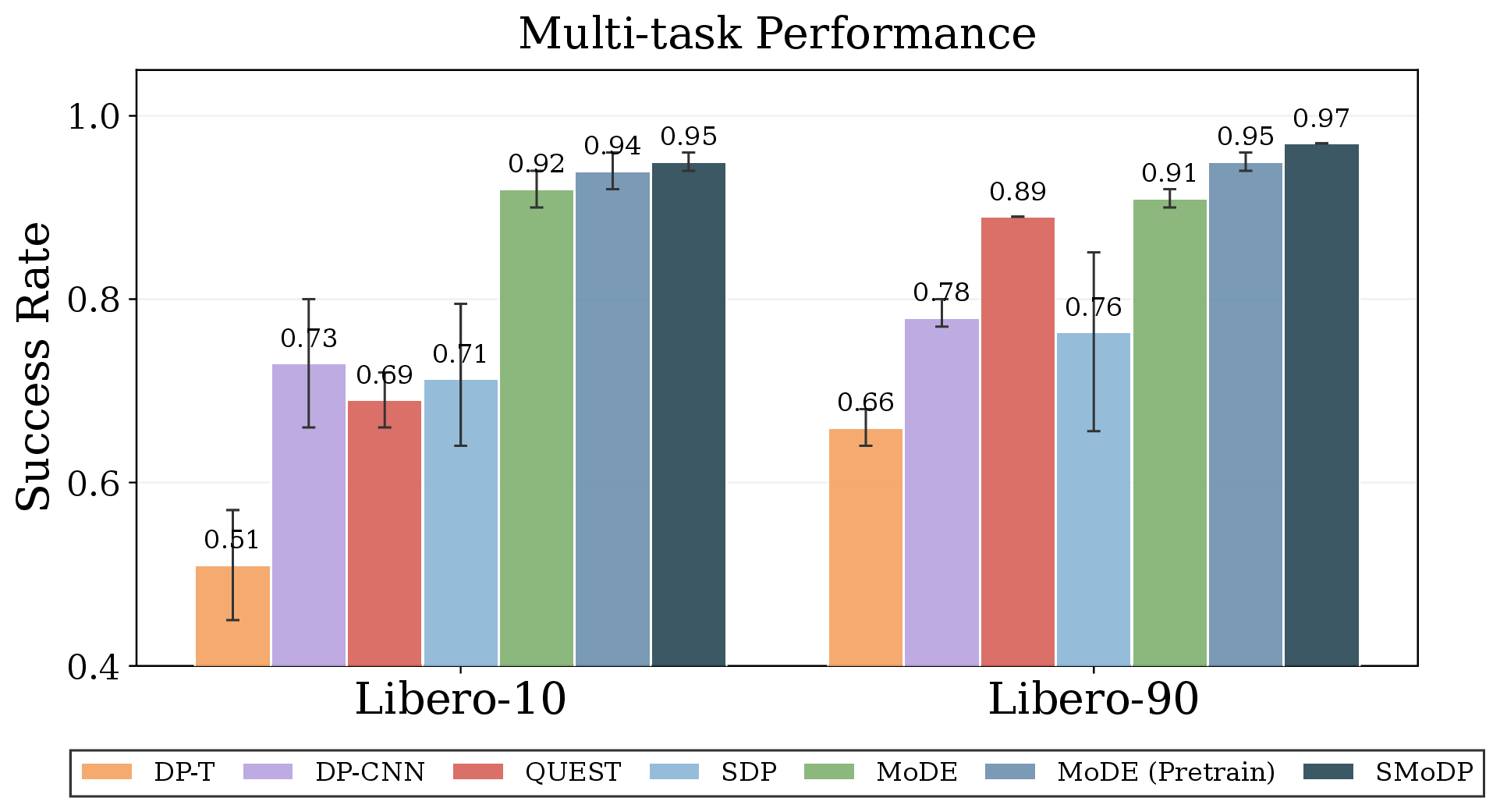
Multi-task Performance
SMoDP achieves the best average success rate on LIBERO-10 and LIBERO-90 among evaluated baselines.
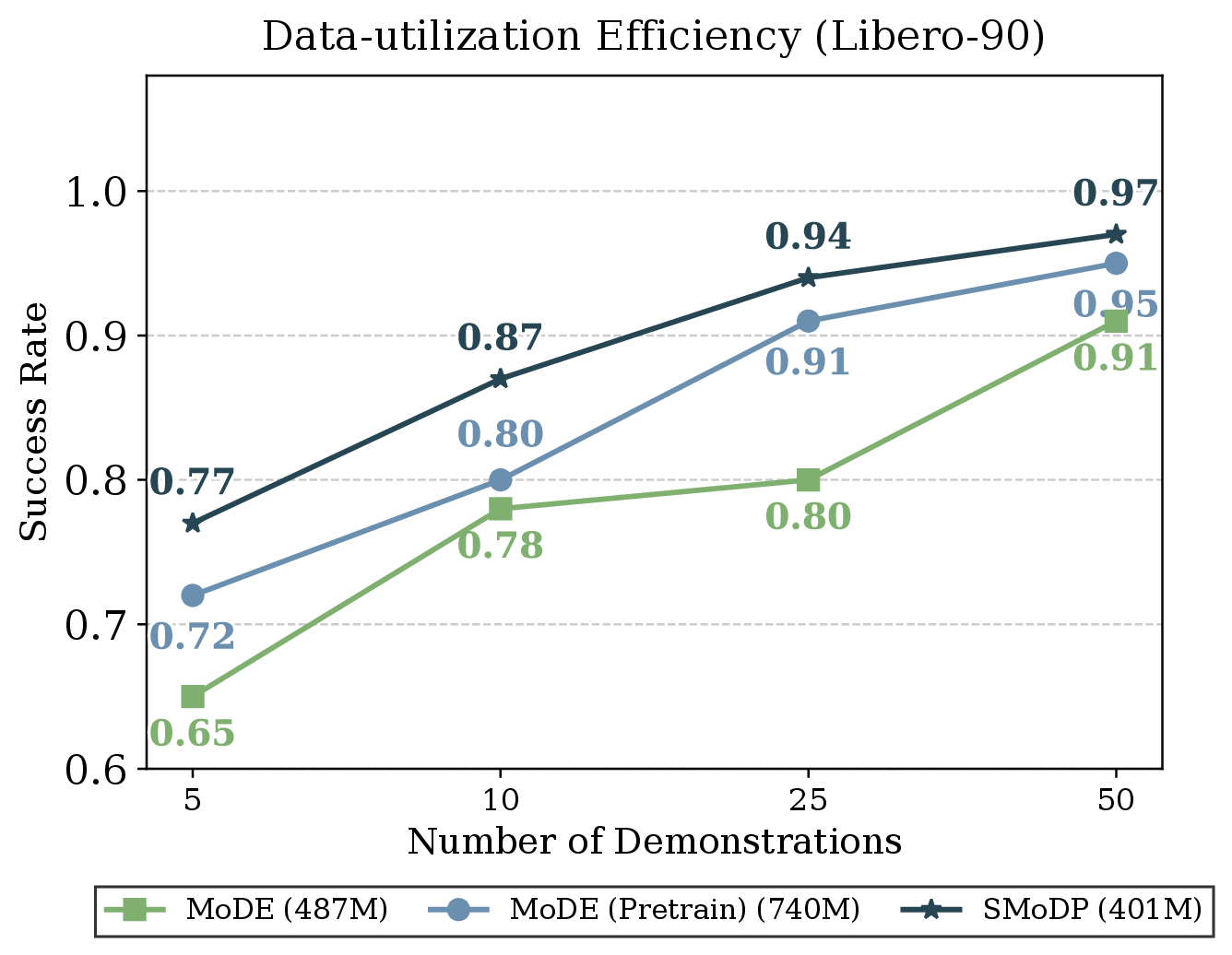
Data Efficiency
SMoDP performs better with fewer demonstrations and remains preferable to pretrained MoDE despite using fewer parameters.
Few-shot Compositional Transfer
SMoDP freezes experts and only fine-tunes the skill predictor and router.
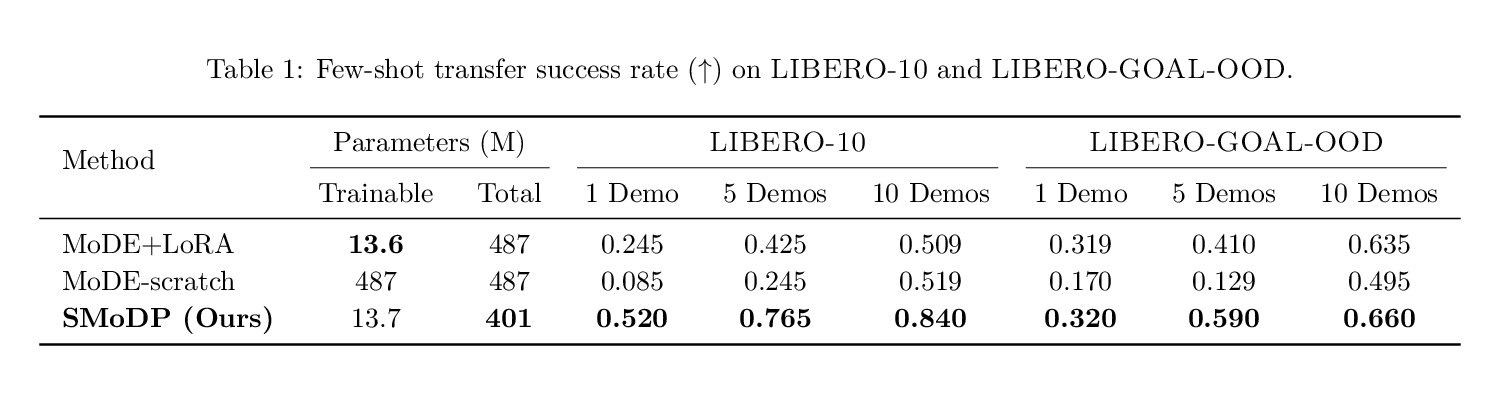
For LIBERO-90 to LIBERO-10 and LIBERO-OBJECT/GOAL to LIBERO-GOAL-OOD transfer, SMoDP updates only 13.7M parameters and achieves the best performance under 1/5/10-demo adaptation.
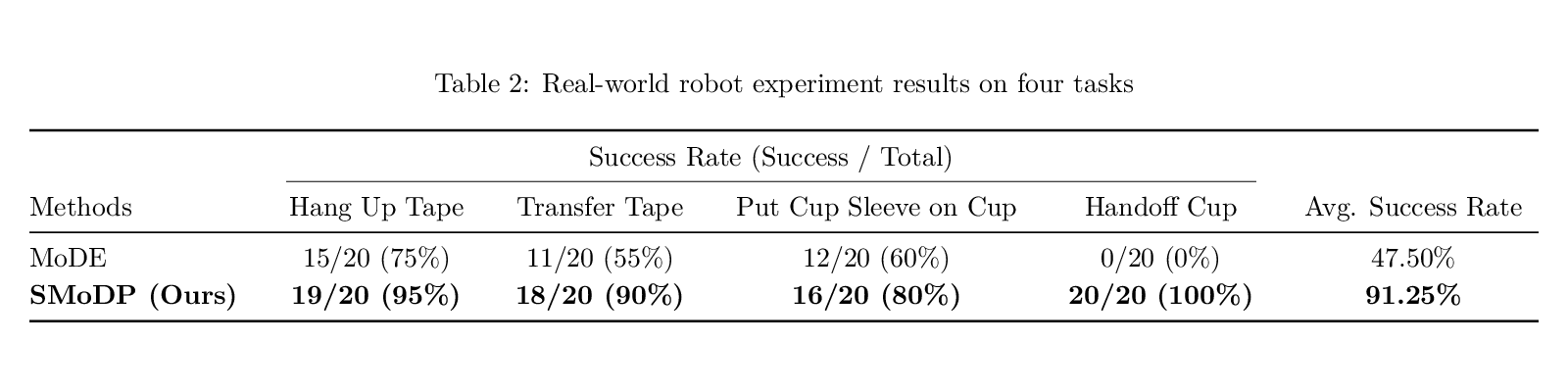
Real-world ALOHA
On four real-world bimanual tasks, SMoDP improves average success rate from MoDE's 47.50% to 91.25%.
Hang Up Tape
Transfer Tape
Put Cup Sleeve on Cup
Handoff Cup
BibTeX
@inproceedings{deng2026smodp,
title={Semantically Structured Mixture-of-Experts for Compositional Robotic Manipulation},
author={Deng, Chengyu and Chen, Guanqi and Chen, Yizhou and Liu, Zejia and Ruan, Zhiwen and Chen, Guanhua and Pan, Jia},
booktitle = {Robotics: Science and Systems (RSS)},
year={2026}
}